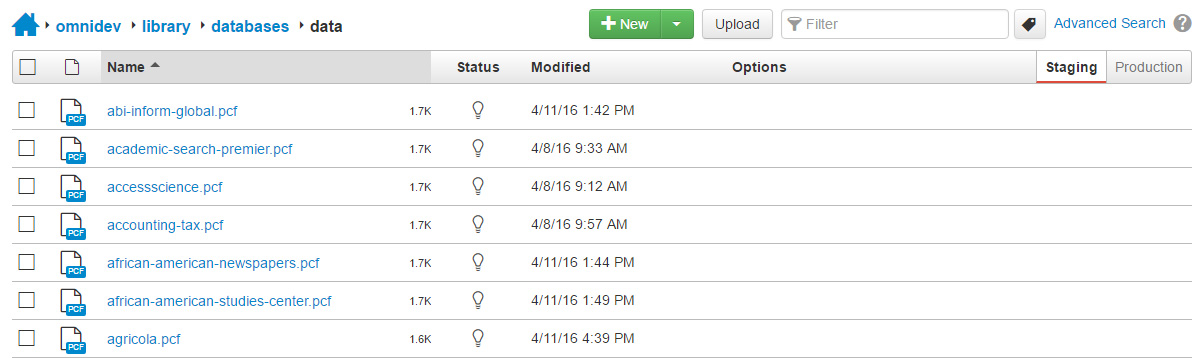
The Library website at the University of Northern Colorado has a list of academic journals that they subscribe to. This list is constantly changing and needs to be updated by Library staff. The academic journals are organized in an A-Z listing as well as organized by subject. Each journal can belong to a single subject or multiple subjects.
If this was a SQL database there would be three tables. One table for the journals, a table for subjects and a table linking between the subjects and the journals.
With OU Campus ‘tags’ can be added to the page to create the link between journals and subjects. On each subject page, the journals with that individual tag get pulled in.
“Data Files”
Data files are standalone .pcf files that are similar to a database entry. Each file contains the information for a single journal entry: Journal Name, Description, URL and a dropdown for Active, which will tell the XSL if the data file should be pulled in or not. Line 9 defines the page type as library-database which will be used in case other OU users assign tags to their pages.
<?xml version="1.0" encoding="utf-8"?>
<?pcf-stylesheet path="/xsl/data-file.xsl" title="Library Database" extension="html"?>
<!DOCTYPE document SYSTEM "http://commons.omniupdate.com/dtd/standard.dtd">
<document xmlns:ouc="http://omniupdate.com/XSL/Variables">
<ouc:info><tcf>section.tcf</tcf><tmpl>properties.tmpl</tmpl></ouc:info>
<page type="library-database"/>
<ouc:properties label="config">
<parameter section="Database Information" name="database-name" type="text" group="Everyone" prompt="Database Name" >Accounting Journal</parameter>
<parameter name="database-description" type="text" group="Everyone" prompt="Description" >This is an academic journal that has articles about accounting.</parameter>
<parameter name="database-url" type="text" group="Everyone" prompt="URL" >http://www.google.com/</parameter>
<parameter section="Active" name="active" type="select" group="Everyone" prompt="Active">
<option value="yes" selected="true">True</option>
<option value="no" selected="false">False</option>
</parameter>
</ouc:properties>
</document>
Data File XSL
In the XSL for the Data File, the tags that are associated with the page are looped and displayed:
<xsl:variable name="page-path" select="replace($ou:path, '.html', '.pcf')" />
<xsl:for-each select="doc( concat('ou:/Tag/GetTags?', 'site=', $ou:site, '&path=', $page-path ) )/tags/tag">
<li><xsl:value-of select="name" /></li>
</xsl:for-each>
GetTags() returns a node with the sibling node of
The next step (will take some time but only has to be done once,) is to create a data file for every Library Academic Journal.
Subject Tags
The data files will be pulled in based on the tags that are associated with that data file. Each data file can have an unlimited number of tags associated with it allowing it to belong to an unlimited number of subject areas. A tag needs to be created for each subject area. This may also take some time, and could be been done when the DataFile is being created. A naming convention would be a good idea. For this demo library-database-name. is used.
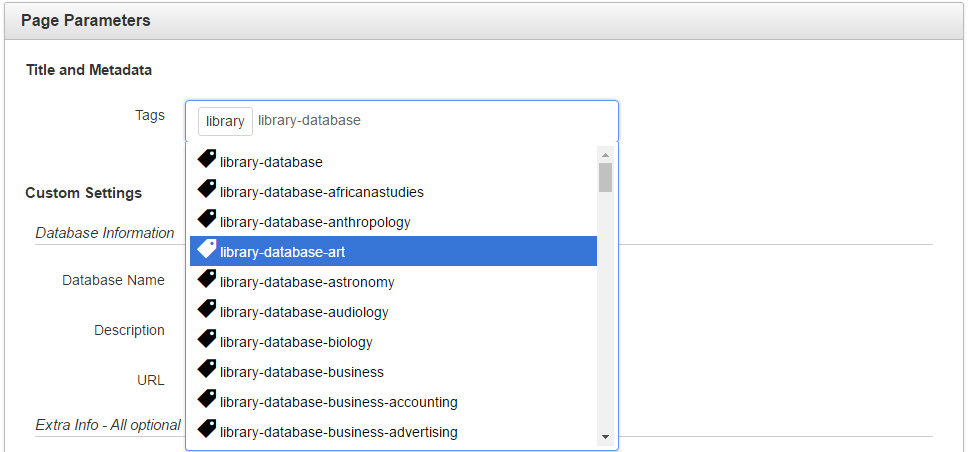
Tags are stored on OU Campus and not with the individual .pcf file, so if you have cloned the repo you will need to add tags to each data file. It would also be a good idea to duplicate the data file to have more than one page to pull in.
Subject Pages
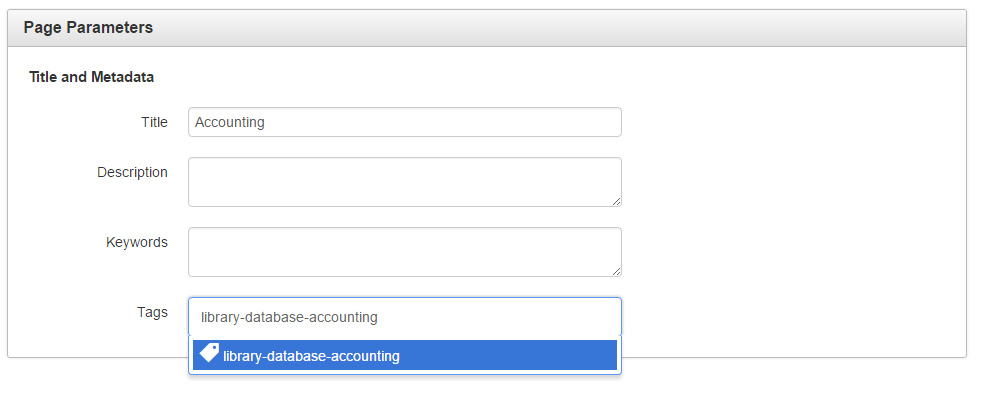
Now that the data files have been created and assigned tags, they need to be pulled into the subject pages. The tag that will be pulled in will be the first tag associated with the subject page. For the demo, the subject page will pull in Accounting Journals. Attach the library-database-accounting tag to this subject page.
Below is the XSL for the subject pages. On line 4 the first tag that is associated with the page is assigned to the variable $page-tag. Then all pages with that tag are are assigned to the variable $tag-select Finally, the data files are looped and the path of each data file is passed to a template to display the content:
xsl:template name="GetDataFilesWithTag">
<!-- Get the current file's path -->
<xsl:variable name="current-page"
select="concat('ou:/Tag/GetTags?', 'site=', $ou:site, '&path=', replace($ou:path, '.html', '.pcf')" />
<!-- Get the first Tag that is associated with this subject listing page -->
<xsl:variable name="page-tag" select="doc( $current-page ) )/tags/tag[1]/name" />
<!-- Get Data Files With the Tag -->
<xsl:variable name="tag-select"
select="doc( concat('ou:/Tag/GetFilesWithAnyTags?site=', $ou:site, '&tag=', $page-tag) )" />
<!-- Loop through the pages that contain the keyword: -->
<xsl:for-each select="$tag-select/pages/page">
<!-- Sort the pages by the path -->
<xsl:sort select="path" />
<!-- Pass the path to a new function to handle the next step -->
<xsl:call-template name="GetContentFromSingleDataFile">
<xsl:with-param name="data-url" select="path" />
</xsl:call-template>
</xsl:for-each>
</xsl:template>
On line 16 of the previous code example, the data file’s path is passed to the function GetContentFromSingleDataFile. More code could be nested here, but breaking it up into multiple templates is easier to read and is better organization and re-usability of code.
GetContentFromSingleDataFile
<!-- Template that takes a URL and formats the content: -->
<xsl:template name="GetContentFromSingleDataFile">
<xsl:param name="data-url" />
<!-- Get the full path to the data file: -->
<xsl:variable name="full-path" select="concat($ou:root, $ou:site, $data-url)" />
<!-- Get Data File Content -->
<xsl:variable name="page-content" select="doc($full-path)/document" />
<!-- Check to see if it is a data file since the subject page also has this tag associated with it -->
<xsl:if test="$page-content/page/@type = 'library-database'">
<!-- Check to see if the data file is set to 'active' -->
<xsl:if test="$page-content/ouc:properties[@label='config']/parameter[@name='active']/option[@selected='true'] = 'True'">
<!-- Display the Journal's Information: -->
<h2><xsl:value-of select="$page-content/ouc:properties[@label='config']/parameter[@name='database-name']" /></h2>
<p><xsl:value-of select="$page-content/ouc:properties[@label='config']/parameter[@name='database-description']" /></p>
<a href="{$page-content/ouc:properties[@label='config']/parameter[@name='database-url']}">Open Database</a>
<hr/>
</xsl:if>
</xsl:if>
</xsl:template>
This code snippet takes the path as a parameter (line 3) and creates a variable of the full path to the file (line 6). Next, the content of the page is stored as a new variable (line 9). Lines 6 and 9 could be combined into a single variable.
Line 12 checks to see if the page-type is a library-database file. This is important since anyone can assign tags to a page in OU Campus. By selecting only pages with the page type of library-database no renegade pages will be pulled in.
Checking to make sure the Active dropdown is set to True (line 15) will allow end users to turn on and off databases as access is changed.
Finally, it the database name, description and link are outputted.
Wrap Up
The final step would be to create subject pages for each subject. UNC has about 50 academic journal subjects and a page will be created for each one as well as a master A-Z listing. If there is interest, I can write up an article about the listing page which won’t use the tags since every journal will get pulled in.
This is my first technical post so feedback is welcomed. The full source code is on GitHub.
Updates
- Feb 5, 2021 - Since I don't work at UNC anymore, they removed the demo and the library no longer uses OU Campus to manage their journals.